
Что такое наблюдаемость и мониторинг? Концепции, преимущества и инструменты
Автор статьи — EPAM Solution Architect Рахул Муджнани.

Введение
Мы живем в эпоху стремительной цифровой трансформации, в которой компании адаптируются к разнообразным технологическим стекам и создают программные решения на базе облачных, локальных, гибридных или распределенных систем — в зависимости от нужд и задач бизнеса.
Это помогает решать сложные бизнес-проблемы и в то же время создает новые трудности, связанные с архитектурой системы, ее производительностью, масштабируемостью, сложностью, безопасностью, устойчивостью и удобством эксплуатации. Как следствие, компаниям приходится тщательно следить за приложениями, сетью, хранилищем и инфраструктурными слоями своих систем. Важно понимать, что даже несколько минут и особенно часов простоя системы могут значительно повлиять на доход бизнеса и доверие пользователей.
Для того, чтобы правильно понимать индикаторы и контролировать состояние своих систем, инженерные команды должны сконцентрироваться на мониторинге и наблюдаемости (англ. observability):
- Мониторинг помогает определить, КОГДА возникает проблема.
- Наблюдаемость дает понимание, ПОЧЕМУ проблема возникла.
Давайте рассмотрим обе концепции более подробно.
Что такое мониторинг?
Мониторинг — это постоянное наблюдение за системой для обнаружения любого аномального поведения и уведомления о нем. Мониторинг направлен на отслеживание конкретных показателей, связанных с бизнес-целями, и принятии соответствующих мер, когда достигаются определенные пороговые значения.
К примерам метрик мониторинга можно отнести использование ЦП, использование памяти, пиковую нагрузку, время отклика или частоту ошибок в сервисах.
За последние годы подходы к мониторингу изменились. Для того, чтобы компании могли собирать полезную информацию о своих программных системах, традиционного мониторинга уже недостаточно. У современных систем может быть множество состояний: они могут быть представлены облачными, гибридными или мультиоблачными приложениями.
У инженерных команд должны быть определенные механизмы, чтобы точно определить, как поведение конкретного сервиса может повлиять на поведение продукта и, как следствие, на пользовательский опыт.
Что такое наблюдаемость?
Наблюдаемость связана с пониманием состояния системы, для этого проводится анализ логов, метрик и трассировок (трейсов). Она помогает проанализировать, что именно происходит в каждом контексте системы, чтобы предсказать ее будущие состояния и сгенерировать полезные данные. Наблюдаемость дает детальное представление о поведении системы и более полный контекст для лучшего понимания ее поведения изнутри.
Внедрение наблюдаемости помогает распознать ранние признаки потенциальных проблем. Основная цель состоит в том, чтобы сохранять контроль и решать проблемы до их широкого воздействия на систему. Чем выше уровень наблюдаемости системы, тем более эффективно инженерные команды могут понимать состояние системы и решать потенциальные проблемы. Это особенно важно, если вы хотите, чтобы система соответствовала показателям уровня обслуживания (англ. Service Level Indicators, SLI) и целям уровня обслуживания (англ. Service Level Objectives, SLO).
Хотя термины «мониторинг» и «наблюдаемость» схожи и часто используются как синонимы, их характеристики отличаются, особенно в контексте гибридных облачных и мультиоблачных систем. Однако следует отметить, что наблюдаемость нельзя эффективно использовать без мониторинга: мониторинг необходим для того, чтобы команда узнала о том, что проблема возникла, но он не поможет разобраться с первопричиной. Именно здесь в игру вступает наблюдаемость, которая позволяет выявить основную причину этой проблемы.
Преимущества наблюдаемости и мониторинга
1. Взвешенные решения: благодаря наблюдаемости инженерные команды могут лучше понимать свои программные системы и принимать продуманные решения относительно производительности, безопасности и архитектуры системы и усовершенствования инфраструктуры. Она также помогает выявить скрытые проблемы и идентифицировать узкие места в программных системах.
2. Оперативная осведомленность и сотрудничество: наблюдаемость способствует культуре оперативной осведомленности, когда компаниям удается объединять различные потоки информации для оценки производительности системы, выявления потенциальных утечек, определения причин потенциальных сбоев и введения профилактических мер до возможного влияния на общую производительность или доступность продукта. Это часто приводит к культурной трансформации внутри организаций, поскольку команды внедряют проактивный подход, который стимулирует мышление постоянного развития.
3. Производительность и мощность систем: надежные системы наблюдаемости и мониторинга помогают компаниям добиться полной видимости всей инфраструктуры, включая локальные и облачные среды. Это дает возможность тщательно отслеживать состояние и производительность хостов, сервисов и контейнеров, а также создавать кастомизированные метрики и запускать оповещения в соответствии с конкретными SLO организации. Кроме того, такой подход облегчает контроль над затратами для компаний, которые внедрили эластичную инфраструктуру.
4. Упрощенный процесс устранения неполадок: наблюдаемость существенно ускоряет процесс устранения проблем, помогая инженерным командам находить и анализировать первопричину с высокой точностью. Доступ к контекстной информации и точное определение источника проблемы позволяют командам понять, почему возникла проблема, и оперативно принять меры для ее устранения.
5. Автоматический фидбек: инженерные команды могут получать ценную обратную связь по недавно выпущенному коду из продакшна. Это способствует оперативным улучшениям и повышению общей производительности системы и ускоряет итеративный процесс разработки.
6. Раннее обнаружение инцидентов и автоматизированные оповещения: комплексный подход к наблюдаемости и мониторингу играет ключевую роль в улучшении как бизнес-показателей, так и пользовательского опыта. Обнаружение проблем на ранней стадии с помощью автоматизированных оповещений позволяет оперативно принимать меры, чтобы предотвратить масштабное ухудшение качества сервисов. Команды также могут задать условия оповещения и допустимые пороги для своевременных уведомлений в случае каких-либо утечек.
7. Мониторинг внешних интеграций: в современном цифровом мире системы зависят от услуг сторонних поставщиков, API и облачных провайдеров. Наблюдаемость и мониторинг распространяются и на эти важные зависимости, а это дает возможность тщательно оценивать производительность и надежность внешних сервисов. Такой подход позволяет организациям планировать и проводить необходимые действия, когда возникают проблемы.
Концепции наблюдаемости и мониторинга

Инструментирование
Инструментирование — ключевой шаг для обеспечения наблюдаемости. Оно определяет, как вы хотите наблюдать внутренние процессы приложения и какие события вы хотите измерить, чтобы понять, что происходит в коде при ответе на конкретный запрос.
- Используйте точки данных, чтобы создать полезный набор данных телеметрии, который можно запрашивать по необходимости. Эффективная практика наблюдаемости требует наличия правильного инструментирования для сбора телеметрических данных о системах.
- Чтобы упростить сбор телеметрических данных (метрики, логи, трейсы), пользуйтесь библиотеками инструментирования, такими как OpenTelemetry, Micrometer и другие. Они помогают инструментировать код, чтобы не зависеть от вендора. Так у команд есть более широкий выбор опций при анализе логов, метрик и трейсов.
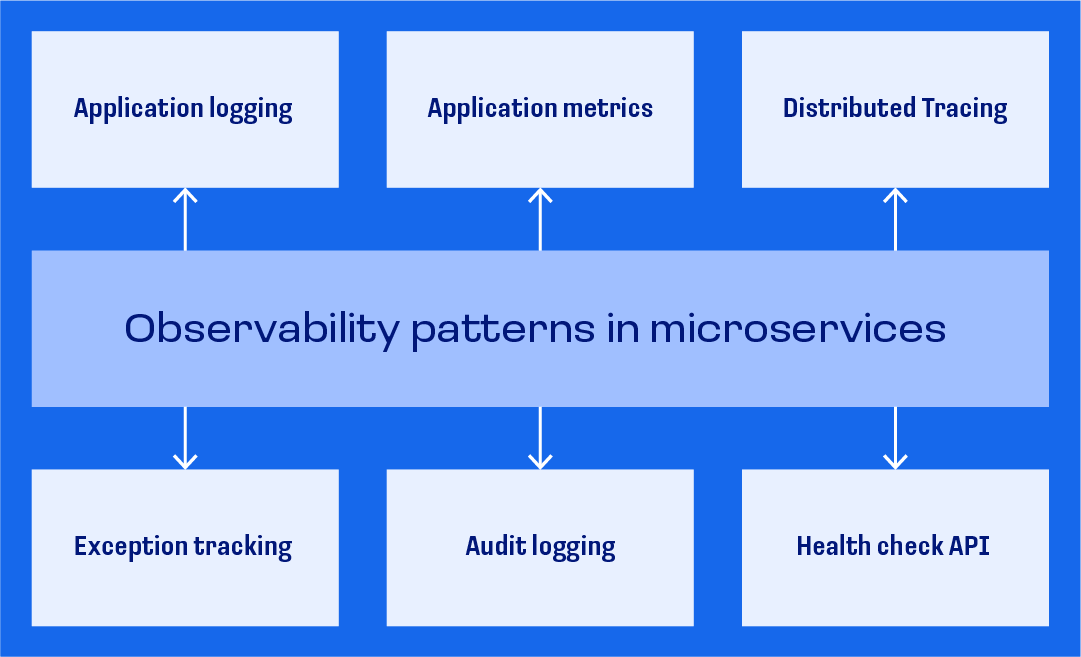
Метрики, логи и трейсы
Основы наблюдаемости связаны с метриками, логами и трейсами. Их агрегация и корреляция в централизованном месте очень важны для того, чтобы наладить успешный процесс наблюдаемости.
Метрики
Метрики — это числовое представление данных, измеренных в течение определенных временных интервалов. Примерами метрик могут быть использование ЦП, использование памяти, сетевой трафик, время отклика, состояние контейнеров, частота ошибок, задержки и пр.
- Определите наиболее важные метрики — от инфраструктуры до сервисов приложения.
- Свяжите метрики с порогами и SLO, чтобы они были выполнимыми и полезными.
Логи
Логи — это неизменяемые события и ошибки с временными метками, которые произошли в системе за какое-то время.
- Создайте согласованный шаблон логирования с структурированного формата, такого как JSON или XML; это упрощает запрос данных логов.
- Используйте логи как мощный инструмент во время устранения неполадок.
- Логи должны содержать достаточно информации, чтобы можно было проанализировать последовательность событий, которые привели к определенному поведению в системе.
- Индексируйте логи для создания запросов и аналитики.
События
События представляют собой единицу работы и содержат всю необходимую информацию для выполнения определенной задачи. События могут не быть похожи на структурированные логи. Как правило, одно событие состоит из группы логов. В первую очередь события полезны для получения инсайтов о продукте и опыте пользователей.
Трейсы
Трейсы отслеживают прохождение определенного запроса через различные системы, чтобы предоставить информацию о потоке транзакций. Трейсы, как и метрики, становятся более полезными, если добавить к ним контекст.
Дашборды визуализации
После получения телеметрических данных следует добавить их визуальное представление для удобного просмотра важных точек данных.
- Используйте инструменты визуализации данных и дашборды для наглядного и понятного представления данных мониторинга.
- Используйте запросы с вашим набором данных, чтобы создавать четкие и интуитивно понятные дашборды. Это помогает командам и заинтересованным лицам выявлять тренды, аномалии и узкие места в производительности.
Инструменты мониторинга производительности приложений помогут собрать данные в графики и диаграммы, чтобы данные были представлены комплексно.
Оповещения и пороги
Процесс настройки оповещений — неотъемлемая часть в обеспечении эффективной наблюдаемости. Инструменты наблюдаемости предоставляют удобные средства для настройки оповещений на основе различных метрик. Если конкретная метрика превышает заранее установленный порог, система немедленно запускает оповещения. Эти оповещения могут легко интегрироваться с системами уведомлений или инструментами in-call оповещений.
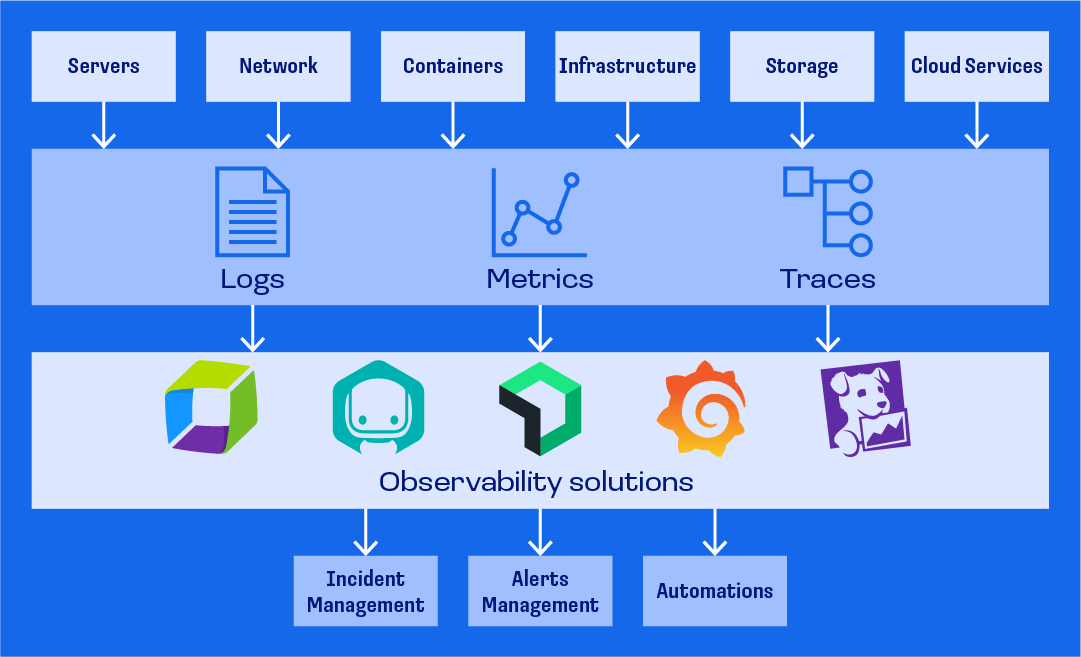
Инструменты наблюдаемости и мониторинга
Инструменты наблюдаемости помогают пользователям связывать компоненты инфраструктуры с компонентами приложения, понимать интеграцию всех служб и выявлять аномалии в поведении.
Вы можете использовать следующие инструменты:
Заключение
Мониторинг и наблюдаемость играют ключевую роль в обеспечении бесперебойной работы современных программных систем, которые, как правило, состоят из микросервисов, контейнеров и облачных или мультиоблачных сред приложений. Когда компании придерживаются лучших практик, принятых в отрасли, стараются соответствовать установленным стандартам и развивают культуру наблюдаемости, они могут быть уверены в том, что их системы работают надежно и максимально эффективно.
Мнения, выраженные в статьях на сайте, принадлежат исключительно авторам и могут не совпадать с мнением редакции или участников Anywhere Club.

.png?auto=webp)
